Untersuchung von Beteiligungsdaten
- Studiengang: Data Science (Master)
- Modul: Projekt Data Science
- Zeitraum: Wintersemester 2020/2021
- Prüfer: Prof. Dr. Korinna Bade
- Projektpartner: Lars Schütz, Hochschule Anhalt
Zusammenfassung
In Deutschland haben Bürger die Möglichkeit, die Probleme in ihren Lebenssituationen oder ihre Vorschläge zur Stadtplanung mittels einer Bürgerbeteiligung an Verwalter bzw. Beamte und Vertreter der jeweiligen Stadt näher zu bringen. Diese Beteiligungen werden dann von Vertretern der Stadt untersucht und bearbeitet.
Das Problem im Umgang mit diesen Beteiligungen für die bearbeitende/zuständige Person besteht darin, dass ähnliche Beteiligungen gleich behandelt werden müssen, um unnötige Konflikte oder gar rechtliche Folgen zu vermeiden. Darüber hinaus ist die manuelle Auswertung der Beteiligungen zeitaufwendig und umständlich. Um dieses Problem zu beseitigen, war die Hauptaufgabe des durchgeführten Projekts, Ähnlichkeiten in den Beiträgen mit Hilfe von Methoden des Maschinellen Lernen zu finden. Die ähnlichsten Beiträge und die entsprechenden Entscheidungen können dann dem Vertreter präsentiert werden, um die Bearbeitungszeit und die Wahrscheinlichkeit einer fehlerhaften Analyse zu minimieren.
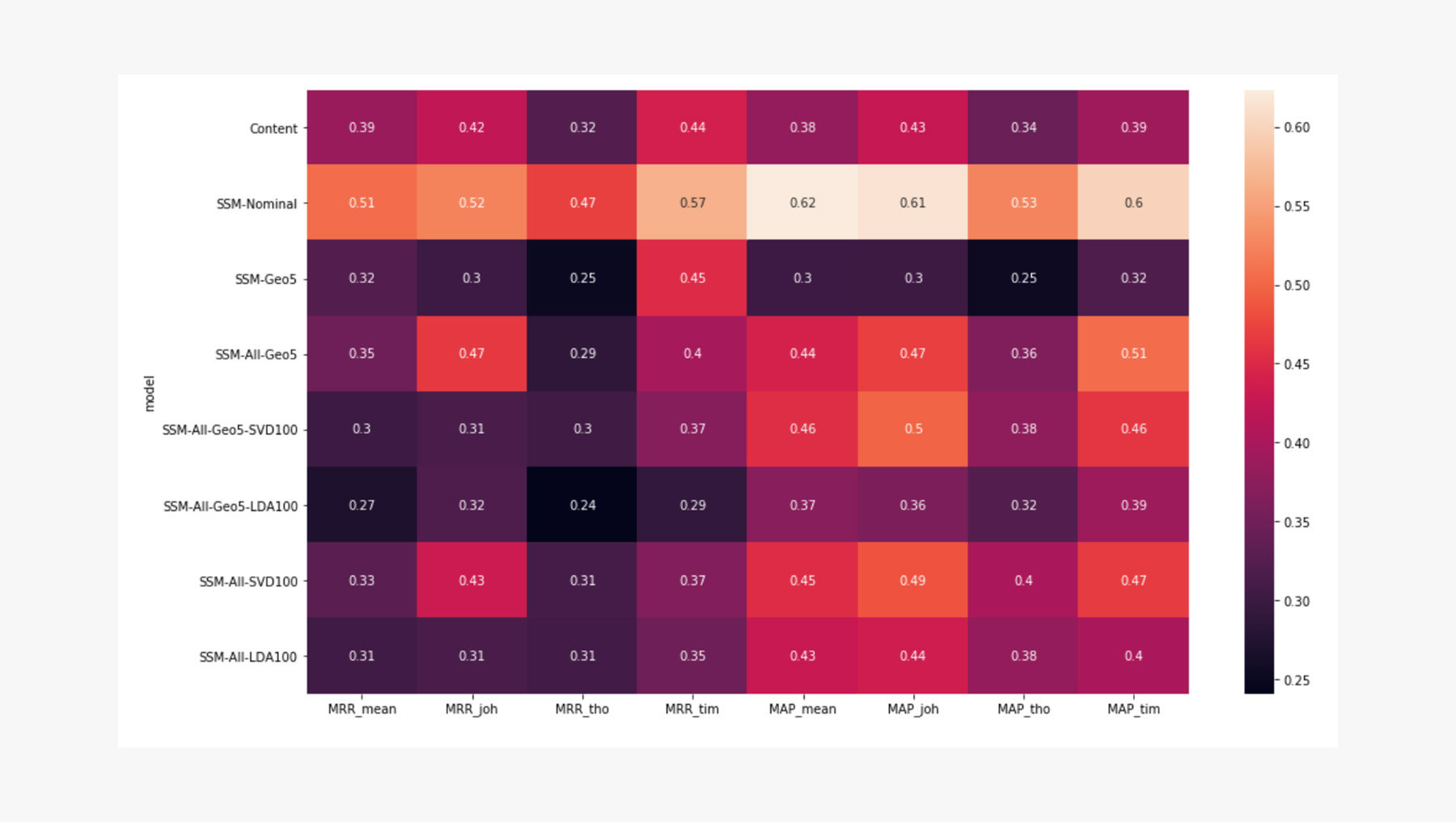
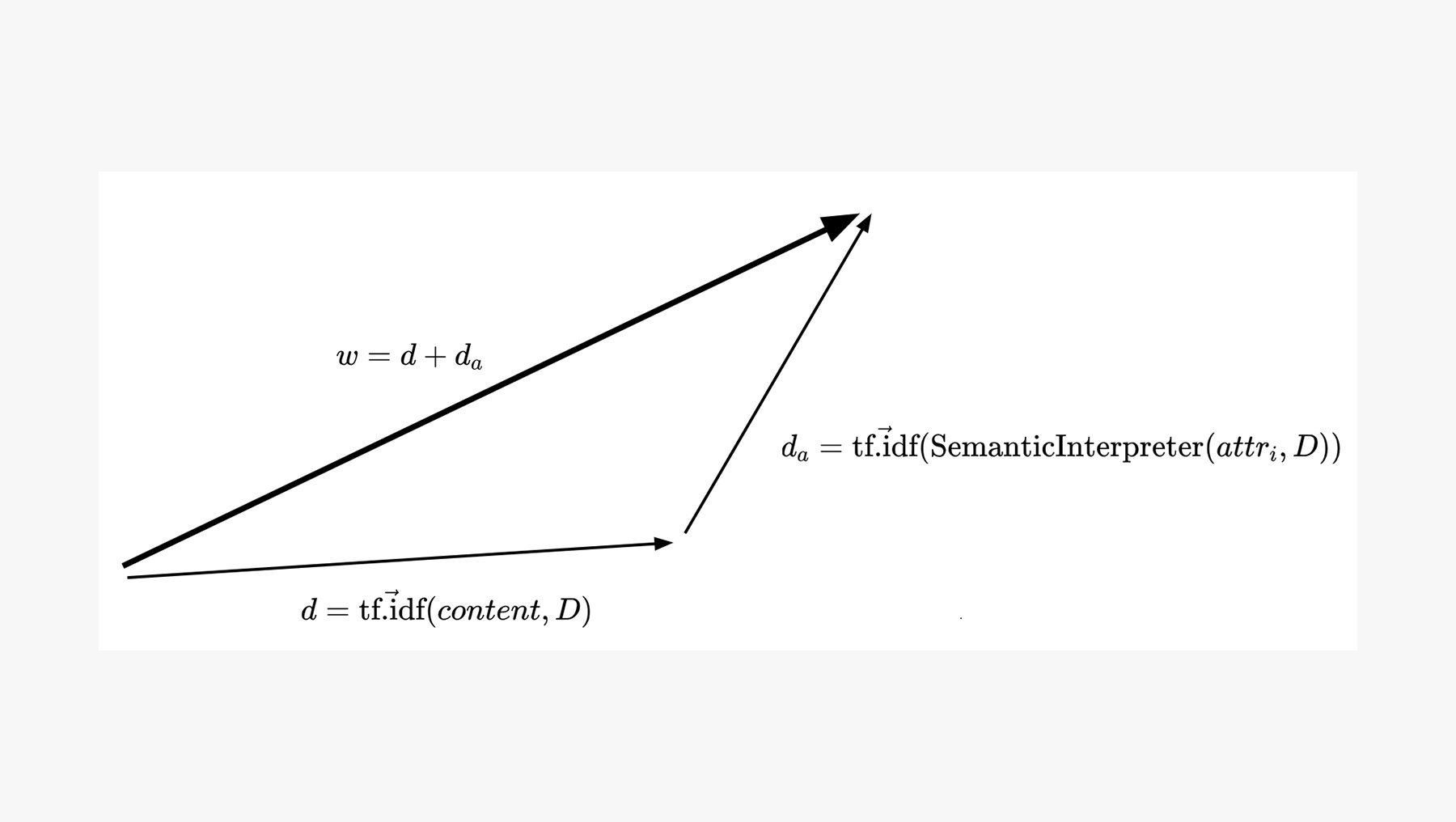
Eine Besonderheit des zur Verfügung gestellten Datensatzes der Bürgerbeteiligungen ist ihr semistrukturiertes Format. Das heißt, neben dem unstrukturierten Beitragstext, in dem ein Bürger sein Anliegen beschreibt, verfügt eine Beteiligung über zusätzliche Merkmale wie Kategorien oder Ortsangaben. Im Rahmen dieses Projekts wurde demnach untersucht, inwiefern dieses semistrukturierte Format die Qualität eines Information-Retrieval-Systems positiv beeinflussen kann. Daher wurde ein Semantic Interpreter verwendet, um Attribute, Geo-Cluster und weitere nominale Merkmale als TF-IDF-Vektor darzustellen, genau wie den Beitragstext. Auf diese Weise kann die Vektor-Repräsentation mit TF-IDF-Gewichtung des Beitragstextes mit dessen Merkmalen durch Vektoraddition kombiniert werden. Durch das Beibehalten der ursprünglichen Form bzw. Dimension der Term-Dokument-Matrix wurde eine Verbesserung bei der Themenmodellierung (engl. Topic Modeling) erwartet. Das Endergebnis zeigt jedoch, dass die Verwendung aller Merkmale die Qualität des Modells nicht verbesserte, wobei die Qualität mittels Mean Reciprocal Rank und Mean Average Precision gemessen wurde. Auch eine anschließende Themenmodellierung konnte die Qualität nicht verbessern. Obwohl der Ansatz zunächst nicht das gewünschte Ergebnis lieferte, konnten mit der sorgfältigen Wahl eines nominalen Merkmals bessere Ergebnisse erzielt werden.
Betreuer/in

